



.jpg)



(3).jpg)

.jpg)

"Mở kho” trí tuệ và dữ liệu sẽ thúc đẩy phát triển y học chính xác tại Việt Nam
Cập nhật lúc: 21/12/2020, 13:31
Cập nhật lúc: 21/12/2020, 13:31
“Dữ liệu cần được chia sẻ, thay vì nghiên cứu rồi cất giữ” và cơ chế chia sẻ dữ liệu linh hoạt là điều kiện cần để thúc đẩy cộng đồng nghiên cứu Y sinh cùng phát triển - như GS. Vũ Hà Văn, Giám đốc Khoa học VinBigdata (thuộc Tập đoàn Vingroup) chia sẻ. Vì thế, mới đây, Viện VinBigdata đã vừa công bố ra mắt Hệ thống quản lý, phân tích và chia sẻ dữ liệu Y sinh lớn nhất Việt Nam.
Năm 2018, Vingroup công bố dự án Xây dựng cơ sở dữ liệu biến thể di truyền của người Việt do VinBigdata chịu trách nhiệm triển khai. Với việc giải trình tự toàn bộ hệ gen của hơn 1.000 người Việt khỏe, đây là dự án có quy mô lớn nhất Việt Nam trong lĩnh vực này tính đến thời điểm hiện tại. Bộ dữ liệu thu thập được đảm bảo tính đại diện khi đáp ứng sự đa dạng về vùng miền cùng các đặc điểm sinh học khác như: giới tính, độ tuổi (trải dài từ 35-55 tuổi). Sau hai năm, 80% dữ liệu đã được phân tích và chú giải.
Giải trình tự gen không còn là một bài toán mới, đặc biệt khi dữ liệu về hệ gen liên quan chặt chẽ đến bệnh học, hỗ trợ phát hiện sớm, ngăn ngừa bệnh nan y... Việc giải trình tự gen phục vụ điều trị bệnh cũng là xu hướng của nhiều quốc gia trên thế giới như Mỹ, Anh, Úc…. Để việc giải trình tự gen người Việt được nhanh chóng, chính xác, VinBigdata cũng đẩy mạnh kết nối, chia sẻ nguồn lực, dữ liệu với các tổ chức khoa học có uy tín.
Cuối năm 2020, VinBigdata chính thức bắt tay với 21 đơn vị nghiên cứu hàng đầu trong lĩnh vực Y khoa, Sinh học phân tử, Khoa học máy tính, Tin sinh học của Việt Nam và quốc tế. Nổi bật trong số đó có thể kể đến Trung tâm khoa học dữ liệu ứng dụng, Đại học Chicago (Mỹ); Phòng Thí nghiệm hệ gen ung thư, Trung tâm ung thư MD Anderson (Mỹ), Phòng Dịch tễ học và Thống kê sinh học, Viện nghiên cứu Karolinska (Thụy Điển), Trường Khoa học Máy tính, Đại học Tel Aviv (Israel), Viện Sinh học phân tử, Đại học Queensland (Úc), Viện Tin sinh học Singapore, Đại học Y Hà Nội, Đại học Dược Hà Nội, Đại học Bách Khoa Hà Nội…

Hợp tác toàn diện về nghiên cứu, kết nối và chia sẻ học thuật, VinBigdata hướng tới xây dựng mạng lưới nghiên cứu tri thức toàn cầu, làm cầu nối giữa các nhà khoa học Việt Nam với các chuyên gia đầu ngành trên thế giới. Đây là cơ hội để đội ngũ nghiên cứu trong nước tận dụng, tăng tính hiệu quả trong nghiên cứu và phát triển.
Thông qua hợp tác, các bên sẽ cùng tham gia các dự án như: nghiên cứu đặc điểm di truyền quần thể người Việt, phát triển hệ thống quản lý và phân tích dữ liệu gen quy mô lớn, nghiên cứu các giải pháp dự đoán nguy cơ bệnh và đáp ứng thuốc dựa trên gen, phát hiện và cảnh báo vi khuẩn kháng kháng sinh… với kỳ vọng sẽ đưa các giải pháp ứng dụng vào thực tế tại Việt Nam trong 2-3 năm tới.
“Dữ liệu cần được chia sẻ, thay vì nghiên cứu rồi cất giữ”, và cơ chế chia sẻ dữ liệu linh hoạt là điều kiện cần để thúc đẩy cộng đồng nghiên cứu Y sinh cùng phát triển - như GS. Vũ Hà Văn, Giám đốc Khoa học VinBigdata chia sẻ tại sự kiện AI4VN diễn ra vào cuối tháng 11 vừa qua. Đây cũng là một trong những mục tiêu để đội ngũ các nhà khoa học tại VinBigdata phát triển Hệ thống Quản lý, Phân tích và Chia sẻ dữ liệu Y sinh (https://genome.vinbigdata.org) lớn nhất Việt Nam như một “kho dữ liệu mở” phục vụ cộng đồng.
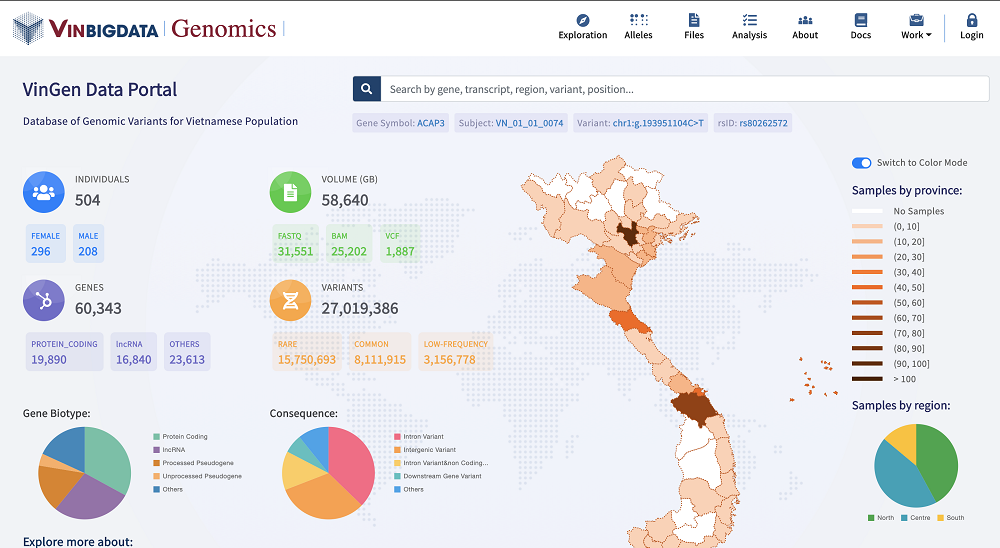
Tính “mở” của hệ thống được thể hiện rõ ngay từ khâu thiết kế, xây dựng, phát triển đến công bố, ứng dụng. Dữ liệu từ dự án 1000 hệ gen người Việt cũng như một số dự án ứng dụng quy mô lớn khác sẽ được chia sẻ thông qua hệ thống này. Hiện tại, hệ thống đang lưu trữ và xử lý hơn 1200 TeraByte dữ liệu của gần 5000 mẫu sinh học theo tiêu chuẩn của Viện Y tế Quốc gia Mỹ (NIH). Thiết kế của hệ thống đảm bảo bảo mật thông tin theo Quy định chung về bảo mật thông tin (GDPR) của châu Âu.

Với hệ thống này, VinBigdata và các đối tác có thể dễ dàng truy cập, tìm kiếm thông tin, phân tích và chia sẻ dữ liệu, đẩy nhanh tiến độ nghiên cứu. Người dùng có thể tra cứu (theo gen, theo biến thể gen, theo từng cá thể, theo mã tra cứu rsID...); tham chiếu, phân tích dữ liệu hệ gen người Việt phục vụ nghiên cứu, phát triển các ứng dụng lâm sàng; chỉ mất dưới 30 phút cho một mẫu phân tích toàn hệ gen. Dự kiến đến cuối năm 2021, hệ thống sẽ cập nhật thêm các bộ dữ liệu từ các dự án nghiên cứu ứng dụng về nguy cơ bệnh và tác dụng phụ của thuốc.
Trong bối cảnh có không ít nghiên cứu xây dựng được nguồn dữ liệu phong phú, có giá trị về người Việt, có khả năng tận dụng cho nhiều đề tài tiếp nối… nhưng gặp bất cập về cơ chế chia sẻ, hệ thống được kỳ vọng sẽ là bước khởi đầu nhằm giải quyết thách thức này, trở thành cổng thông tin dữ liệu mở uy tín, đáng tin cậy của Việt Nam, nhận được sự đóng góp dữ liệu từ cộng đồng nghiên cứu, doanh nghiệp và các tổ chức.

10:22, 14/12/2020
15:25, 03/11/2020
13:30, 18/09/2020